
Tokens
Los tokens no son palabras. Son la unidad técnica, económica y operativa que define cómo funcionan ChatGPT, Claude, Gemini y los agentes de IA modernos.

¡Hola! Soy Oscar 👋, y por aquí estoy de nuevo!!!
Esta imagen es quizás la representación del verdadero terror por estos días:

“Me consumí los tokens!!!! 🤯😭😡
Ya me ha pasado muchas veces, pero la ultima vez que me pasó justo había todo un debate en redes sociales sobre el consumo de tokens y su costo en plataformas como Claude (BTW si quieres volverte un master en Claude, en Junio haré un bootcamp virtual ;) ).
Me causó mucha curiosidad, porque además me pregunté ¿qué carajos son los tokens en realidad?… y no me pude responder!!!
Así que como buen “nerd”, me di a la tarea de investigar, y aquí va lo que encontré.
Si aún no te has suscrito a Xtrategia, te invito a hacerlo dando click aquí
TL;DR
Los tokens son la unidad discreta con la que los LLMs procesan texto.
No equivalen a palabras: pueden ser subpalabras, signos, espacios, bytes o tokens especiales.
Nacieron de una genealogía que une compresión, lingüística computacional, traducción automática y deep learning: BPE, WordPiece, SentencePiece y Transformers.
Hoy son mucho más que una técnica: determinan contexto, coste, latencia, memoria, razonamiento y diseño de producto.
La optimización moderna no consiste en escribir menos, sino en diseñar mejor qué información entra, se resume, se cachea o se recupera.
¿Qué es un token?
En lenguaje común hablamos con palabras. En IA generativa, eso no alcanza.
Cuando escribes:
“Explícame qué son los tokens en inteligencia artificial”
el modelo no recibe esa frase como la ves tú.
Primero pasa por un tokenizador, es decir, una pieza de software que divide el texto en unidades. Cada unidad se transforma en un ID numérico.
El modelo no “lee” palabras: procesa una secuencia de números.
Un token puede ser:
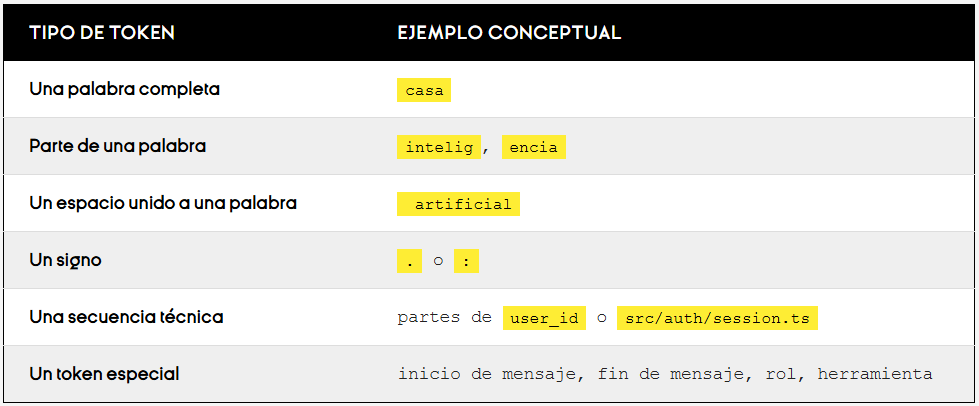
Al final, es una unidad computacional.
Hugging Face, la comunidad global de AI, describe la tokenización como un pipeline con varias etapas:
Normalización,
Pre-tokenización,
Modelo de segmentación
Post-procesamiento.
Primero se estandariza el texto; luego se divide en unidades preliminares; después se aplica un modelo como BPE, WordPiece o Unigram (algoritmos de tokenización de subpalabras fundamentales en el procesamiento del Lenguaje Natural (PLN) moderno); y finalmente se pueden añadir tokens especiales necesarios para el modelo.
Esta distinción importa porque muchas personas calculan costos o ventanas de contexto usando palabras.
Es un error.
Un contrato legal, un archivo JSON, una conversación en español, una ruta de código o una frase en japonés pueden tener relaciones muy distintas entre caracteres, palabras y tokens.

La regla práctica es esta: los tokens son la forma en que el lenguaje se vuelve computable para un LLM.
📌 Si llegaste hasta aquí, es porque te interesa ir más allá de la teoría, así que te invito a Xtrategas, mi comunidad para profesionales que lideran en producto, operaciones, tech, innovación y transformación digital.
¿Te unes?
Por qué existen los tokens
Los tokens existen porque hay que resolver un problema básico:
¿cómo convertir lenguaje humano abierto, irregular y multilingüe en una secuencia finita que una red neuronal pueda procesar?
Hay tres opciones obvias, y ninguna es perfecta.
Procesar caracteres. Esto permite representar cualquier palabra, incluso palabras nuevas, errores o nombres raros. El problema es que las secuencias se vuelven muy largas. Una frase corta puede convertirse en decenas o cientos de unidades.
Procesar palabras completas. Los idiomas tienen millones de formas posibles: conjugaciones, plurales, errores, nombres propios, palabras técnicas, neologismos, hashtags, rutas de archivo, código y expresiones mixtas. Un modelo con vocabulario fijo no puede tener una entrada dedicada para cada posible palabra.
Usar unidades intermedias: subwords. Son piezas más pequeñas que palabras, pero más grandes que caracteres. Este enfoque permite representar palabras raras como combinación de fragmentos conocidos.
Este último, fue uno de los avances clave de la traducción neuronal.
En 2015, Sennrich, Haddow y Birch argumentaron que la traducción automática es un problema de vocabulario abierto, mientras que los modelos operan con vocabularios fijos. Su solución fue codificar palabras raras y desconocidas como secuencias de subword units, usando ideas inspiradas en Byte Pair Encoding.
La idea es muy interesante: no necesitas que el modelo haya visto cada palabra completa; necesitas que haya aprendido piezas suficientemente útiles para recomponerla.

Quién inventó los tokens
La respuesta honesta es: nadie inventó los tokens modernos en un solo acto.
La palabra “token” ya existía en lingüística, procesamiento de lenguaje natural y recuperación de información.
Lo que hoy usamos en LLMs es el resultado de varias tradiciones técnicas que convergieron.
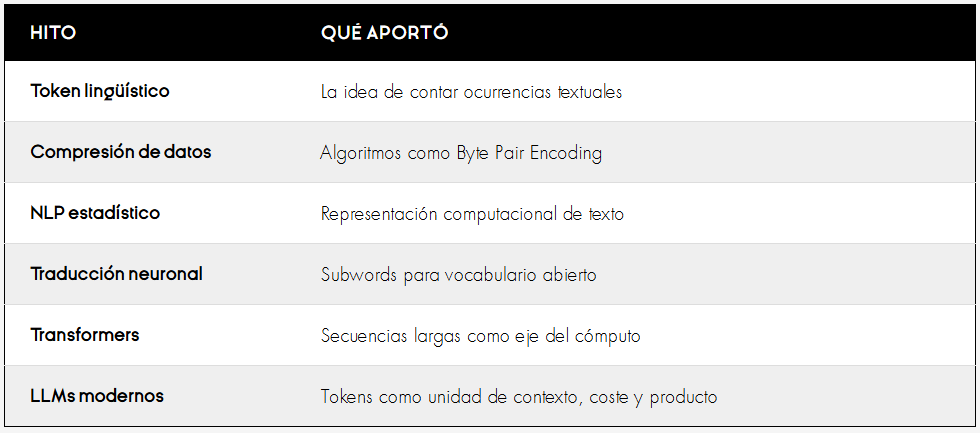
Byte Pair Encoding nació como técnica de compresión. Luego fue adaptada a lenguaje natural.
WordPiece fue usado en modelos como BERT (modelo de lenguaje de IA desarrollado por Google (2018) para el Procesamiento del Lenguaje Natural).
SentencePiece llevó la tokenización subword a un enfoque independiente del idioma, capaz de entrenarse desde texto crudo, sin asumir que el texto ya viene separado por espacios.
El Transformer (un tipo de arquitectura de red neuronal que transforma o cambia una secuencia de entrada en una secuencia de salida. Para ello, aprenden el contexto y rastrean las relaciones entre los componentes de la secuencia) hizo que todo esto se volviera más relevante.
Por eso, si queremos responder “quién inventó los tokens”, la mejor respuesta es:
Los tokens modernos son una convergencia entre lingüística computacional, compresión de datos, traducción automática y deep learning. No tienen un único inventor; tienen una genealogía técnica.
Si aún no te has suscrito a Xtrategia, te invito a hacerlo dando click aquí:
Por qué los tokens importan tanto en IA
Los tokens importan por cinco razones: contexto, costo, latencia, calidad y control.
1. Contexto
La ventana de contexto define cuántos tokens puede considerar un modelo en una interacción. Cuando se dice que un modelo soporta 200K, 400K o 1M tokens, se habla del tamaño máximo del “espacio de trabajo” disponible.
Pero esa ventana no está reservada solo para tu prompt. También puede contener instrucciones de sistema, historial, archivos, imágenes, herramientas, resultados de herramientas, memoria y tokens de razonamiento.
2. Costo
La mayoría de sistemas comerciales cobran por tokens. Si tu aplicación carga documentos enteros en cada consulta, el coste puede crecer de forma silenciosa. Un prototipo que parece barato con diez usuarios puede volverse caro con diez mil.
3. Latencia
Más tokens suelen significar más tiempo. El modelo debe procesar más información, mantener más contexto y producir más salida. Aunque las infraestructuras mejoran, no existe magia: una petición enorme normalmente tarda más que una petición breve.
4. Calidad
Más contexto no siempre mejora la respuesta. A veces la empeora. El modelo puede recibir demasiada información irrelevante, perder la señal importante o arrastrar errores de conversaciones anteriores. Anthropic, por ejemplo, llama “context engineering” al conjunto de estrategias para curar y mantener el conjunto óptimo de tokens durante la inferencia de agentes.
5. Control
Las reglas de seguridad, las instrucciones del sistema, los esquemas de herramientas y las restricciones de salida ocupan tokens. Si el contexto se llena de ruido, queda menos espacio para instrucciones críticas, evidencia relevante y verificaciones.
En una frase: los tokens son el presupuesto cognitivo del modelo.
Tokenización no es lo mismo que facturación por tokens
Esta distinción es clave.
Tokenización es el proceso técnico de convertir texto en unidades discretas, que eventualmente los modelos puedan entender y procesar.
Facturación por tokens es el modelo económico que muchos proveedores usan para cobrar el uso de sus modelos.
Los tokens no nacieron para cobrarle al usuario.
Nacieron porque los modelos necesitaban una forma eficiente de representar lenguaje.
Pero una vez que los tokens se volvieron la unidad de trabajo del modelo, también se volvieron una buena unidad de facturación.
Esto tiene sentido: procesar 200.000 tokens suele requerir más cómputo que procesar 2.000. Generar 10.000 tokens de salida cuesta más que generar 300.
Mantener contexto largo consume memoria.
Razonar durante más pasos puede aumentar el presupuesto de salida o de pensamiento interno.
Por eso hoy muchos proveedores cobran por millón de tokens de entrada, tokens de salida, tokens cacheados, tokens de razonamiento o contexto largo.
Anthropic, por ejemplo, publica precios por millón de tokens y documenta prompt caching, batch processing y ventanas de contexto para sus modelos Claude.
Lo visible y lo invisible: ¿por qué el consumo sorprende al usuario?
Uno de los grandes problemas de experiencia de usuario en IA es que el consumo real de tokens no coincide con lo que vemos como usuarios.

Este punto explica muchas frustraciones recientes con herramientas de AI.
El usuario puede sentir: “solo hice dos preguntas”.
Pero el sistema puede haber leído archivos, ejecutado comandos, procesado resultados, consultado memoria, preservado historial y razonado antes de responder.
La interfaz muestra conversación.
La infraestructura procesa una cadena de eventos.
El caso Claude: cuando los tokens se vuelven una crisis de producto

Claude es un caso especialmente útil porque muestra el choque entre tres fuerzas: modelos cada vez más capaces, usuarios más intensivos y límites de uso difíciles de comunicar.
En 2026, el costo real de usar Claude aumentó entre 2x y 5x para muchos equipos, sin que Anthropic haya subido sus precios oficialmente. Lo que cambió fue todo lo demás: la arquitectura del modelo, el comportamiento por defecto, la duración del caché y el modelo de facturación para clientes enterprise.
El resultado es una brecha entre lo que dice el precio por token y lo que realmente aparece en tu factura.
La primera causa es el nuevo tokenizador de Opus 4.7, lanzado en abril de 2026.
Anthropic lo documenta con esta frase que poca gente leyó: “This new tokenizer may use up to 35% more tokens for the same fixed text.”
El precio por millón de tokens no cambió, pero el número de tokens que genera el mismo texto sí aumentó hasta un 35%. Para workloads en español, JSON o código estructurado, el impacto puede ser aún mayor y nadie recibió una notificación al respecto.
La segunda causa son los tokens de razonamiento (Extended Thinking / Adaptive Thinking), se cobran a precio de output, el más caro, aunque no los veas en la respuesta.
Cuando activas thinking en Claude, el modelo genera un proceso interno de razonamiento antes de responderte. Ese proceso puede consumir miles de tokens que se cobran completos, incluso si configuras la API para ocultar ese razonamiento.
La documentación oficial lo dice explícitamente: “You are billed for the full thinking process, not the thinking content visible in the response.”
Una llamada estándar de $0.033 puede costar $0.093 con un presupuesto de razonamiento de 4,000 tokens, un 180% más caro. Y en Claude 4, el nivel de esfuerzo high viene activado por defecto.
La tercera causa. Anthropic redujo la duración del caché de prompts de 1 hora a 5 minutos, sin ningún anuncio público.
Los desarrolladores lo descubrieron por ingeniería inversa de sus propios logs. El prompt caching permite almacenar contexto repetitivo (system prompts, documentos de referencia) para que las llamadas subsecuentes lo lean al 10% del costo normal.
Con caché de 5 minutos, cualquier pausa mayor invalida ese ahorro y obliga a reescribir el contexto al 125% del costo estándar. Un desarrollador que analizó 1,140 sesiones documentó el impacto con números concretos: antes del cambio gastaba $6.28 por día; después del cambio, $15.54, un incremento del 147% producido por un solo ajuste.
A esto se suma un efecto que opera en cada sesión larga: el contexto acumulativo.
En conversaciones extensas con herramientas agénticas, cada nuevo request reenvía todo el historial anterior.
Una sesión que empieza con 2,000 tokens de contexto llega a 40,000 tokens en el turno 10. Investigaciones documentadas muestran que en sesiones largas el 98.5% de los tokens se gastan releyendo historial, solo el 1.5% corresponde al output real de valor.
No es que Claude sea ineficiente; es que la forma de interactuar importa tanto como el modelo que eliges.
La buena noticia es que la mayoría de estos costos son controlables con decisiones de arquitectura, no con cambios de proveedor.
Un equipo de seis personas en Asia documentó cómo pasó de $2,400 a $680 por mes en cuatro semanas, sin cambiar el modelo principal.
Las tres palancas principales:
Configurar el parámetro
effortdel Adaptive Thinking enmediumolowpara tareas que no requieren razonamiento profundo (clasificación, extracción de datos, conversión de formatos)Usar routing por complejidad, Haiku 4.5 para tareas mecánicas cuesta un 92% menos que Sonnet sin pérdida de calidad
Gestionar el tamaño del contexto con sesiones enfocadas en lugar de conversaciones eternas. Anthropic también ofrece un 50% de descuento vía Batch API para procesamiento no urgente, una palanca que pocos equipos aprovechan.
La conclusión que se impone en 2026 no es que Claude sea demasiado caro, es que el juego cambió.
La era de usar el modelo más potente para todo, en modo conversacional ilimitado, con contexto que crece sin freno, ya no es económicamente viable a escala.
Los equipos que van a ganar no son los que encontraron el modelo más barato, sino los que construyeron una capa de orquestación inteligente que usa el modelo correcto, con el nivel de razonamiento correcto, en el momento correcto.
Madrona Venture Capital lo resumió bien: “The constraint paradoxically produces better agent systems.” El costo más alto, bien entendido, es una fuerza de diseño que te obliga a construir mejor.
El mito del contexto infinito
Una ventana de 1M tokens suena como la solución definitiva. No lo es.
Más contexto ayuda. Permite analizar documentos largos, mantener sesiones complejas y trabajar con repositorios grandes.
Pero no elimina los problemas de coste, latencia, ruido y selección de información.
La evolución puede verse así:

Una ventana grande es como una mesa enorme.
Puedes poner más documentos encima, pero si la llenas sin orden, trabajarás peor. El modelo puede tener acceso a más información, pero también a más ruido.

Por eso la disciplina emergente no es “meter más contexto”.
Es ingeniería de contexto: decidir qué entra, qué se resume, qué se recupera bajo demanda, qué se elimina y qué se mantiene estable.
Del prompt engineering al token management
Durante 2023 y 2024 se habló mucho de prompt engineering. En 2025 y 2026, la conversación se está moviendo hacia algo más amplio: context engineering y token management.
El prompt sigue siendo importante, pero ya no basta. En productos reales, el rendimiento depende de todo el flujo:
qué instrucciones se cargan siempre,
qué memoria se conserva,
qué documentos se recuperan,
qué herramientas se describen,
qué outputs se guardan,
qué se cachea,
qué se resume,
cuándo se reinicia una sesión.
La idea es simple: si gastar más tokens ahorra horas de trabajo humano, puede ser racional. El riesgo es convertir esa lógica en despilfarro sin medición.
Para founders y PMs, la pregunta correcta es:
¿Estamos gastando tokens para producir valor o estamos usando contexto como sustituto de diseño estructural?
No es lo mismo.
Cómo gestionar y optimizar tokens
Optimizar tokens no significa escribir todo más corto. Significa diseñar mejor el flujo de información.
1. Medir antes de optimizar
No puedes controlar lo que no mides. Para texto plano, librerías como tiktoken permiten estimar tokens en modelos de OpenAI; su repositorio lo describe como un tokenizador BPE rápido para sus modelos.
En aplicaciones reales, sin embargo, el conteo local puede quedarse corto. Herramientas, imágenes, archivos, wrappers de chat, memoria y razonamiento pueden alterar el conteo final.
2. Separar contexto estable y variable
El contenido que se repite debe mantenerse estable: instrucciones de sistema, reglas de estilo, definiciones de herramientas, políticas. El contenido variable debe ir después: la pregunta concreta, el archivo nuevo, el caso actual.
Esto ayuda al caching y reduce reprocesamiento.
3. Recuperar en vez de pegar todo
No pegues todo el PDF. No metas todo el repositorio. No cargues toda la base de conocimiento.
Usa recuperación: chunking, embeddings, búsqueda semántica, filtros por metadatos o selección previa. El objetivo no es que el modelo vea todo. El objetivo es que vea lo relevante.
4. Compactar conversaciones largas
Las sesiones largas necesitan resumen. Pero resumir bien no significa “hacerlo más corto” sin criterio. Una buena compactación conserva:
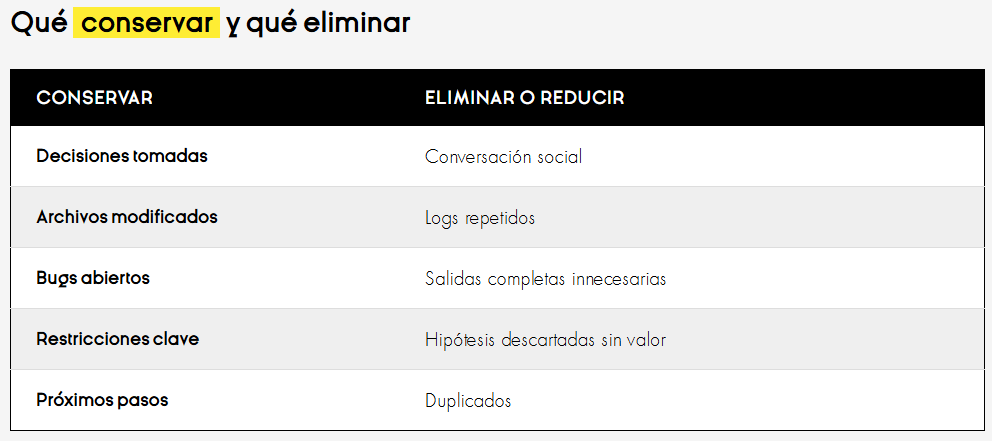
Anthropic ha publicado material sobre compaction y context engineering para evitar degradación en tareas agentic largas.
5. Reducir outputs de herramientas
Los logs son consumidores silenciosos de contexto.
Un test que imprime miles de líneas puede consumir más tokens que el prompt original. En flujos de desarrollo, conviene pedir explícitamente:
“No pegues logs completos; muestra solo las 20 líneas relevantes y resume el resto.”
6. Ajustar razonamiento según tarea
No todas las tareas necesitan razonamiento profundo. Clasificar tickets, reformatear texto o resumir un correo no debería consumir el mismo esfuerzo que depurar una condición de carrera o diseñar arquitectura.
El caso Claude Code mostró precisamente que cambiar el esfuerzo de razonamiento por defecto puede afectar de forma visible la percepción de calidad.
7. Reiniciar sesiones cuando cambie la tarea
Arrastrar contexto antiguo puede ser cómodo, pero caro. Si cambias de tarea, conviene limpiar o abrir una sesión nueva. Si una subtarea genera mucho ruido, usa un subagente o una conversación separada y devuelve solo el resumen útil al hilo principal.
Mal prompt vs buen prompt
Un prompt que quema tokens rápido:
Revisa todo el repositorio, lee todos los archivos, ejecuta todos los tests,
pega los logs completos, explica toda la arquitectura y no pierdas ningún detalle.Ese prompt parece ambicioso, pero es ineficiente. Obliga al agente a explorar demasiado, conservar demasiado y devolver demasiado.
Un prompt mejor:
Objetivo: encontrar la causa del bug de login en src/auth y src/session.
Límites:
- Revisa solo esos directorios salvo que encuentres una dependencia crítica.
- No pegues logs completos; resume y muestra máximo 15 líneas relevantes.
- Si necesitas explorar más de 5 archivos, primero entrega un mapa breve.
- Al final responde con: causa raíz, archivos modificados, prueba ejecutada y riesgos.La diferencia es arquitectura de contexto.
Checklist para equipos que construyen con IA
Antes de lanzar una funcionalidad basada en LLMs, un equipo debería responder:

Esta última pregunta es importante. En abril de 2026 también hubo reportes sobre empresas afectadas por interrupciones o restricciones de acceso a servicios de IA. Aunque cada caso tiene su contexto, el patrón es claro: cuando una empresa integra IA como infraestructura crítica, necesita redundancia, observabilidad y planes de contingencia.
Los tokens son una métrica técnica, pero también una métrica de negocio.
Un producto de IA no escala solo porque el modelo sea bueno. Escala si el costo por tarea, la latencia, la calidad y el consumo de contexto están bajo control.
En prototipo, puedes pegar PDFs completos, arrastrar conversaciones largas y pedirle al modelo que “revise todo”. En producción, eso se convierte en margen bruto, límites de uso, frustración de usuarios y tickets de soporte.
Las preguntas correctas no son:
¿Cuál modelo tiene más contexto?
¿Cuántos tokens caben?
¿Puedo meter todo?
Las preguntas correctas son:
¿Qué información necesita el modelo para resolver esta tarea?
¿Qué información sobra?
¿Qué puedo cachear?
¿Qué puedo recuperar bajo demanda?
¿Qué debo resumir?
¿Qué nunca debería entrar al contexto?
La diferencia entre un demo impresionante y un producto sostenible suele estar ahí.
Para terminar…
Durante años, hablar de tokens parecía un tema para ingenieros. Ya no.
Los tokens son el punto donde se cruzan arquitectura, experiencia de usuario, costo, memoria, seguridad y estrategia de producto. Son la unidad que decide cuánto puede leer un modelo, cuánto puede recordar, cuánto tarda, cuánto cuesta y cuánto control conserva el sistema.
El caso Claude lo mostró con claridad: incluso con modelos potentes y ventanas enormes, los sistemas agentic pueden consumir contexto de formas invisibles para el usuario. Cuando eso ocurre, el límite deja de sentirse técnico y empieza a sentirse como una ruptura de confianza con el usuario.
La solución no es obsesionarse con contar cada palabra. La solución es diseñar sistemas conscientes del contexto.
Herramienta de la Semana
MarkItDown: La librería open-source de Microsoft que convierte prácticamente cualquier archivo a Markdown: PDFs, Word, Excel, PowerPoint, imágenes, audio, HTML, ZIP.
Lleva más de 40,000 estrellas en GitHub desde su lanzamiento en diciembre de 2024.
La premisa es simple: si los LLMs piensan en Markdown, el primer paso para que la IA entienda tus documentos corporativos es convertirlos al idioma que habla nativamente. Lo que antes requería pipelines complejos de extracción de texto ahora es una línea:
markitdown documento.pdf > documento.md. github.com/microsoft/markitdown
En Mi Radar
“Let’s build the GPT Tokenizer” de Andrej Karpathy: Una clase de 2 horas y 13 minutos donde el ex-Director de AI de Tesla construye un tokenizador desde cero. La cita que se volvió viral: “Tokenization is the source of all suffering” — y explica por qué los LLMs no pueden contar letras, hacen mal la aritmética, y son menos precisos en español que en inglés. Si te interesó la estadística de “34% menos tokens con Markdown que con JSON”, este video es el siguiente nivel de comprensión. Disponible en karpathy.ai/zero-to-hero.html
¿Tienes algun sistema o forma de optimizar tu consumo de tokens? me encantaría leerte…
Gracias por leerme.
Si esta newsletter te resultó útil, compártela con un líder de tu red que siga usando IA sin muchos resultados. Nos ayuda a crecer y a ellos les puede cambiar la perspectiva.
Nos leemos la próxima semana.
Oscar Durán - @duranoscarf en instagram y Linkedin

Comparte Xtrategia Newsletter con alguien que creas le puede agregar valor.
Fuentes citadas
Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units. *Proceedings of ACL 2016*. [arXiv:1508.07909](https://arxiv.org/abs/1508.07909)
Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. *NeurIPS 2017*. [arXiv:1706.03762](https://arxiv.org/abs/1706.03762)
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. [arXiv:1810.04805](https://arxiv.org/abs/1810.04805)
Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. *EMNLP 2018*. [aclanthology.org/D18-2012](https://aclanthology.org/D18-2012/)
Liang, P., et al. (2023). Language Model Tokenizers Introduce Unfairness Between Languages. *EMNLP 2023*. [arXiv:2305.15425](https://arxiv.org/abs/2305.15425)
The Token Tax: Systematic Bias in Multilingual Tokenization (2025). [arXiv:2509.05486](https://arxiv.org/abs/2509.05486)
Problematic Tokens: Tokenizer Bias in Large Language Models (2024). [arXiv:2406.11214](https://arxiv.org/abs/2406.11214)
SpaceByte: Towards Deleting Tokenization from Large Language Modeling (2024). [NeurIPS 2024](https://arxiv.org/html/2404.14408)
Byte Latent Transformer: Patches Scale Better Than Tokens (2025). [ACL 2025](https://aclanthology.org/2025.acl-long.453.pdf)
Why Do Large Language Models (LLMs) Struggle to Count Letters? (2024). [arXiv:2412.18626](https://arxiv.org/html/2412.18626v1)
Video: “Let’s build the GPT Tokenizer” (2024). Neural Networks: Zero to Hero series. [karpathy.ai/zero-to-hero.html](https://karpathy.ai/zero-to-hero.html)
OpenAI — Tokenization: [platform.openai.com/tokenizer](https://platform.openai.com/tokenizer)
OpenAI — tiktoken: [github.com/openai/tiktoken (https://github.com/openai/tiktoken)
Anthropic — Vision & Tokens: [platform.claude.com/docs/en/build-with-claude/vision](https://platform.claude.com/docs/en/build-with-claude/vision)
Hugging Face — Tokenization Algorithms: [huggingface.co/docs/transformers/en/tokenizer_summary](https://huggingface.co/docs/transformers/en/tokenizer_summary)
Hugging Face — BPE: [huggingface.co/learn/llm-course/en/chapter6/5](https://huggingface.co/learn/llm-course/en/chapter6/5)
Hugging Face — WordPiece: [huggingface.co/learn/llm-course/chapter6/6](https://huggingface.co/learn/llm-course/chapter6/6)
Google SentencePiece: [github.com/google/sentencepiece](https://github.com/google/sentencepiece)
a tener muy en cuenta!
Muy interesante
Gracias por compartir